¿Qué es la ciencia de datos?

La ciencia de datos crea los modelos de machine learning y permite a las compañías obtener conocimientos a partir de una gran cantidad de datos.
Catalogada por la revista Harvard Business Review (HBR) como “la profesión más sexy” del siglo XXI, el data science atraviesa un presente inmejorable de mucha empleabilidad, estabilidad y buenos salarios. Los científicos de datos tienen las puertas abiertas para encontrar trabajo en muchos sectores, ya sea en la sanidad, financiero, artes, etc. Incluso muchos trabajan de manera remota mientras viajan por el mundo. En este artículo, te explicamos en qué consiste la ciencia de datos y por qué ha ido ganando tanta importancia esta rama laboral.
¿Qué es data science?
La ciencia de datos se refiere al uso interconectado de los datos. Un dato por separado no nos ofrece más información de la que se ve a simple vista. La ciencia de datos crea los modelos de machine learning que permiten a las empresas obtener información a partir de una gran cantidad de datos, automatizando un proceso de filtración que anteriormente era lento y limitado. De esta forma las organizaciones pueden aportar soluciones innovadoras y más efectivas en tiempo real para situaciones complejas, ya sea en el análisis del mercado, de la competencia, de marketing, entre otras.
¿Qué competencias debe tener un científico de datos?
El diagrama de Venn sobre la ciencia de datos, creado por Drew Conway, CEO y fundador de Alluvium, ilustra las competencias que debe tener un profesional para trabajar como un data scientist.
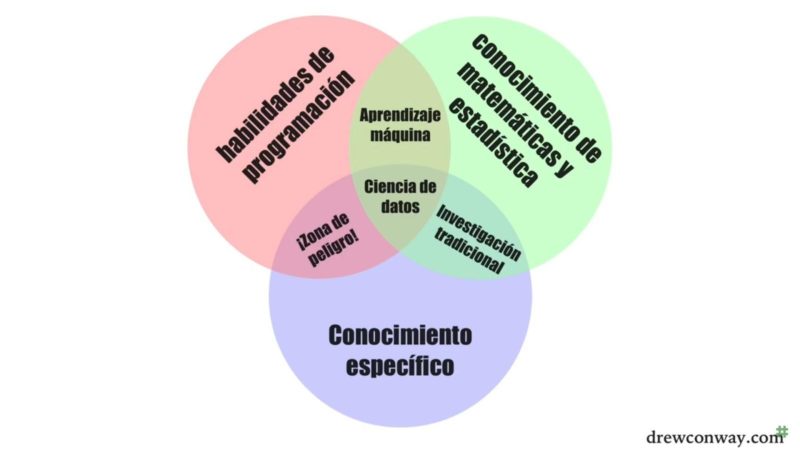
Fuente: Diagrama de Venn sobre la ciencia de datos
Es una forma clara de entender las competencias para trabajar en el prometedor mundo de la ciencia de datos:
- El conocimiento de las matemáticas y la estadística es fundamental en el trabajo de un data scientist. Aunque no es necesario tener un doctorado en dichas ciencias, para tratar los datos es muy importante dominar la regresión lineal y entender sus coeficientes.
- El dominio en entornos y lenguajes de programación, sobre las bases de datos, la inteligencia artificial (IA) y el machine learning (ML), son necesarios para extraer y procesar los datos. Además se requiere de una mente altamente entrenada en algoritmos.
El conocimiento específico es muy importante para extraer la información que permita aplicarlo de manera útil. Es decir, saber en qué quieres emplear los datos, cuáles son tus objetivos, problemas y qué preguntas quieres resolver.
¿Cómo funciona la ciencia de datos?
La ciencia de datos ha evolucionado su capacidad analítica, volviéndose de dominio más accesible y estándar. La empresa tecnológica International Business Machines Corporation, más conocida como IBM, ha creado una “Metodología Fundamental para la Ciencia de Datos”, que propone una estrategia para orientar el trabajo que deberían realizar los científicos de datos, la que se señalan como “independiente de las tecnologías, los volúmenes de datos o los enfoques involucrados”.
La metodología tiene diez etapas y cada una de ellas juega un rol importante a la hora de encontrar insights:
- Comprensión del negocio: se identifican los objetivos, los problemas de la empresa y los requerimientos de la solución. De esta etapa depende si los problemas de una compañía se resuelven con éxito.
- Enfoque analítico: se determinan las técnicas estadísticas y de aprendizaje automático más aptas para la solución deseada.
- Requisitos de datos: según los métodos seleccionados se decide qué contenido y formato deben tener los datos.
- Recopilación de datos: se reúnen los recursos de datos para estimar si los existentes son suficientes para solucionar el problema o si es necesario invertir en otros menos accesibles.
- Comprensión de datos: se aplican técnicas de visualización y estadística descriptiva para evaluar la calidad de los datos, analizar su contenido, encontrar los primeros insights y determinar si hacen falta más datos.
- Preparación de datos: se depuran y se combinan los datos provenientes de diversas fuentes y finalmente se transforman en variables de mayor utilidad. Esta etapa suele ser una de las más largas.
- Modelado: se usa la primera versión del grupo de datos para crear modelos predictivos o descriptivos dentro del enfoque analítico definido en la segunda etapa.
- Evaluación: se realizan varias pruebas para diagnosticar la efectividad del resultado que el modelo identificó en un principio.
- Implementación: al desarrollar y validar el modelo se implementa en un proceso operativo.
- Retroalimentación: se obtiene el feedback sobre el rendimiento del modelo implementado. Los científicos de datos lo utilizan para mejorar la precisión y utilidad del modelo.
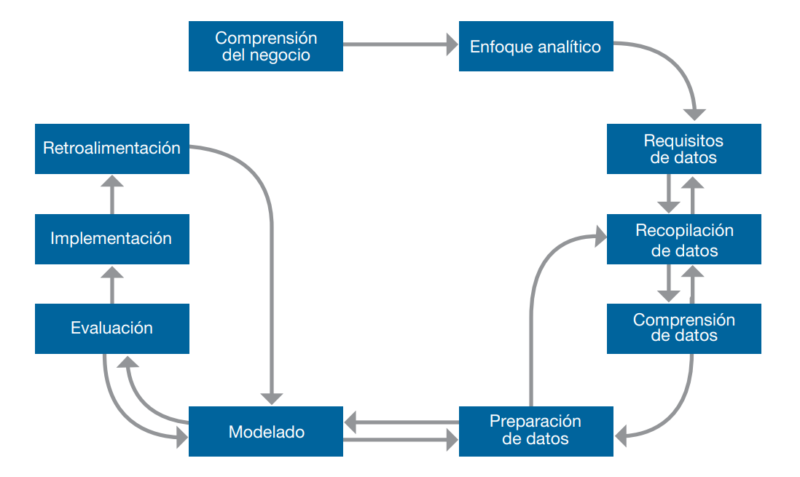
Fuente: IBM
El rol de la inteligencia artificial y el machine learning en la ciencia de datos
La ciencia de datos está directamente relacionada con la inteligencia artificial y el machine learning, aunque los dos juegan un rol muy importante, bajo ninguna circunstancia deben ser considerados como sinónimos.
La inteligencia artificial es una parte nuclear de la ciencia de datos. El objetivo de la inteligencia artificial es que las máquinas imiten las funciones cerebrales. Actualmente la inteligencia artificial puede aprender por sí misma, razonar y auto corregirse sin intervención externa. Aplicar técnicas inteligentes en el análisis de datos promueve el desarrollo de tecnologías de extracción del conocimiento.
El machine learning (ML) automatiza el aprendizaje de un subgrupo de inteligencia artificial y se utilizan técnicas con la finalidad de que “piensen” como humanos. Se les entregan los datos suficientes para que aprendan una tarea específica, la cumplan pero no vaya más allá de su objetivo fijado.
Lo que debes saber sobre data science:
- La ciencia de datos es el uso de datos que permite ofrecer nuevas soluciones a las empresas para analizar el mercado, la competencia o marketing, entre otras.
- Según el diagrama de Venn, un científico de datos debe tener conocimiento de las matemáticas y la estadística, dominar entornos y lenguajes de programación y tener claridad sobre el empleo de los datos.
- La “Metodología Fundamental para la Ciencia de Datos” creada por IBM cuenta con una estrategia de diez etapas desde la identificación de los objetivos y problemas del negocio hasta la retroalimentación.
- La ciencia de datos está relacionada con la inteligencia artificial y el machine learning.



Profesión: Científico de Datos
Conviértete en científico de datos y aprende a construir modelos estadísticos, resolver problemas y expandir la estrategia comercial basada en algoritmos de Machine Learning y Big Data. Crea tus primeros proyectos e inicia tu carrera en uno de los mercados de mayor crecimiento.





